
날아라쩡글이의 블로그입니다.
Set interface, List interface(iterator) 본문
중앙 HTA (2106기) story/java API story
Set interface, List interface(iterator)
날아라쩡글이 2021. 10. 7. 17:00728x90
반응형
- java.Lang.package안에는
- Object,List,Set,Map,ArrayList,HashSet,HashMap,LinkedList,TreeSet,HashTable,Stack,Vector
- Date,Arrays,Collection,Objects,Random,Calendar
- 이 존재한다. 첫번째의 경우는 자료구에 해당되며 오늘 작성할 친구들이다.
Collection Framwork란
- Framwork란 개발방법을 구체화 시켜놓은것
- 자바의 자료구조를 구현해 놓은 것, 자료구조를 구현해 놓은 것
- 자료구조란 객체의 저장/삭제/조회 등의 기능을 제공한것
- 다른 객체를 다룰때, 꺼내고, 삭제하고, 확인할 때 사용하는 방법이다.
- 자바의 모든 자료구조의 구현 클래스는 Collection인터페이스를 구현한 클래스이다.
- Collection인터페이스에 정의된 모든 기능을 구현하고 있다.
- Collection<E>
- ArrayList, LinkedList, HashSet, TreeSet, Vector, Stack등 이게 전부 Collection<E>으로 구현되고 있다.
- method
- add();
- addAll();
- clear();
- contains(Object e); -->e의 객체를 확인하는
- isEmpty -->비어있으면 true, 아니면 false
- Iterator : 반복자
- remove(Object e)
- size
- toArray : 배열에 담아서 반환

대표적인 자료구조이다.

HashSet<E>의 부모의 형태이다.
Collection<E>인터페이스
- 모든 자료 구조 구현 클래스가 반드시 구현할 기능을 정의하고 있다.
- 모든 자료 구조 구현 클래스의 표본이다.
Set<E>인터페이스
- 중복을 허용하지 않는 자료 구조 구현 클래스가 반드시 구현할 기능을 정의하고 있다.
- 중복을 허용하지 않는 자료 구조 구현클래스의 표준이다.
이제부터는 배열을 사용하지 않고, Collection을 이용할 것이다.
자바의 자료구조 특징
- 객체만 저장할 수 있다.
- 제네릭을 사용하기 때문에 객체만 저장할 수 있다.
- 크기가 가변적이다.
- 배열은 크기가 고정적이다.
- 자료구조는 index가 부족시 index가 늘어나고 삭제시 줄어든다.
- 다양한 메소드를 가진다.
Collection<E>제네릭의 형태로 객체만 저장이 가능하고, 기본자료형은 저장할 수 없다.
Set<E>
- 중복을 허용하지 않는다. 동일한 객체가 2개가 저장되지 않는다.
- HashSet<E>
- 가장 많이 사용하는 Set의 구현 클래스이다.
- 같은 객체인지 확인하고, 같은 객체일 경우 해쉬코드가 동일하다.
- 해쉬코드로 동일성 여부를 확인하기 때문에 hash와 equals를 이용하여, 동등성 비교로 재정의 해주는 것이 좋다.
- TreeSet<E>
- 저장되는 요소가 오름차순/ 내림차순으로 정렬되어서 저장된다.
- 제일 처음부터 오름차순/ 내림차순으로 정렬되어서 저장한다.
- new HashSet<객체>();
- 자체적인 저장소를 가졌다.
- 객체의 경우 제네릭타입으로 사용시 바로 지정할 수 있다,
- memory가 허락하는 한 모든 객체를 담을 수 있다.
HashSet<E>
- 여러개의 객체를 담는 배열
- 배열의 인덱스는 index를 알아야한다.
- 인덱스의 범위를 초과하면 java.lang.ArrayIndexOutOfBoundsException이라는 에러가 발생한다.
- 배열의 인덱스,범위를 초과 했을 때 발생하는 오류정보를 포함하고 있는 예외클래스 이다.
- 배열은 자동으로 크기가 증가되지 않는다.
- 그러나 hashSet의 경우 담을 때마다 인덱스가 증가한다.
- HashSet<String> set = new HashSet<>();
- HashSet객체에 데이터(객체)를 저장할 때는 add(E e)메소드를 실행해서 데이터를 저장한다.
- 배열보다 쉽게 데이터를 저장할 수 있다. index를 몰라도 되기 때문이다.
- 저장공간이 부족하면 자동으로 저장공간을 늘린다.
- set.add("문자열");
- 계속해서 들어가고 순서는 그냥 막들어간다. hashcode의 순서대로 입력된다.
| 구분 | 배열 | 콜렉션 |
| 데이터 | 기본자료형, 객체 | 객체 |
| 길이 | 불변 | 가변적 |
| 저장 | 인덱스 필요 | 맨 마지막요소의 끝에 자동으로 저장 |
| 삭제 | 인덱스 필요, 해당부분 데이터 empty | 삭제후 다음요소 해당위치 자동채워짐 |
| Enhanced-for(향상된 for문) | 배열의 끝까지 반복(null exception남) | 요소가 있는 부분까지 반복 |
HashSet<E>의 주요 API사용하기
- import시켜줘야한다.
- Set<String> set = new HashSet<>();
- Set이 구현객체기 때문에 이렇게 만들어 줄 수있다.
- boolean add(E e ) : 지정된 객체를 HashSet객체에 저장한다.
- 저장이 성공하면 true를 반환한다.
- boolean값은 다시 받지 않는다. 저장된걸 확인하면 된다.
- boolean isEmpty(); : HashSet<E>이 비어있으면 true를 반환한다.
- void clear(); : HashSet<E>에 저장된 모든 객체를 삭제한다.
- String toString();
- HashSet<E>는 Object의 toString();메소드를 재정의 했다.
- HashSet<E>는 저장된 객체의 toString()을 실행한다.
- boolean addAll(Collection <? extends E> collection);
- 다른 collection의 구현객체에 저장된 데이터를 전부 저장한다.
- Collection<? extends E >는 Collection구현 객체가 E나 E의 하위타입을 저장하고 있어야한다.
- E는 addAll()메소드를 호출하는 객체의 타입파라미터를 따른다.
- 우리가 생성한 객체는 HashSet<String>이기 때문에 E는 String이다.
- 따라서 Collection<String> , Set<String> , List<String> , HashSet<String>, ArraysList<String>, Vector<String> , LinkedList<String>, Stack<String>이 가능하다.
- <? extends String>으로 변환된다. String은 자식객체가 없기 때문에 String만 가능하다.
- HashSet<E>의 부모인터페이스(Set<E>)에는 set.of() 정적메소드가 존재한다.
- Set<E> Set.of() : Set의 구현객체가 생성한다.
- Set<E> Set.of(E e) :객체가 하나저장된 Set구현객체를 생성한다.
- Set<E> Set.of(E e, E e) :객체가 두 개 저장된 Set구현객체를 생성한다.
- Set<E> Set.of(E e....E e) :객체가 여러개 저장된 Set구현객체를 생성한다.
- int size() : HashSet<E> 객체에 저장된 객체의 갯수를 반환한다.
- boolean contains(Object e) : HashSet<E>객체에 지정된 객체가 존재하면 true를 반환한다.
- 원하는 문자열이 있는지, 객체의 존재여부를 출력한다.
- boolean remove(Object e ) : HashSet<E>객체에 지정된 객체가 존재하면 삭제하고 true를 반환한다.
- System.out.println(set);
- HashSet에 담을 줄 알아야하고, 꺼낼 수 있고, 몇 개 있는지, 비어있는지 확인이 가능해야한다.
- main클래스를 설정하고, 정적 내부 클래스에 매개변수, 생성자, 동등성의 원칙을 위하여 hashCode와 equals에 대한 재정의를 하고, 디버그를 확인하기 위한 toString()도 재정의를 해준다.
- 정적 내부 클래스의 객체를 넣은 HashSet()을 선언한다.
- HashSet<Employee> employees = new HashSet<>();
- employee.add(new Employee(100,"이순신","관리팀"));
- add메소드를 이용하여, 객체를 바로, 바로 추가해준다.
- 동등성의 메소드를 이용해서 입력하지 않으면, 객체는 따로, 따로 생성이 되기 때문에 같은 객체로 보지 않는다.
- 그리고 미리 값을 확인하고 싶어도, 재정의 전인 toString이 클래스 name@ 해시코드로 나오기 때문에
- example_10_06_01_collection.HashSetSample3$Employee@83값으로 출력된다.
- 동등성비교과 toString을 재정의해주면 System.out.println(변수의 이름)을 넣으면
- 재정의 후 Employee [id=100, name=김유신, dept=홍보팀];으로 출력된다.
- addAll()다른 컬렉션을 한꺼번에 담고 싶을 때 사용 가능하다.
- add는 한번씩 밖에 담지 못한다.
TreeSet<E>
- 저장되는 객체를 오름차순으로 정렬해서 저장한다.
- 저장되는 방식에 차이가 있다. 메소드는 동일하다.
- TreeSet에만 사용되는 method가 존재한다.
- java에서는 정렬은 잘 사용되지 않는다.
- 우리가 사용하는 DB에서는 정렬이 완료된 데이터를 가져오기 때문에 많이 사용되지 않는다.
Vector와 Stack은..
- 1.0부터 만들어진 존재들이다.
- 제일 처음에는 메소드가 통일되지 않았다.
- Vector에서는 elements라는 것이 사용되었고, Stack에서는 push, pop이 사용되었다.
- collection<E>는 1.2부터 도입이 되었다.
- 원래는 자료구조에 따라서 전부 메소드가 달랐고,
- Set<E>, List<E>를 만들어서 메소드를 동일하게 만들었다.
- 그래서 1.0에 만들어진 애들은 추가적으로 본인의 고유한 메소드가 존재한다.
- 잘 사용하지 않기 때문에 따로 수업은 진행하지 않는다.
- 고유의 기능이 정보처리기사에 나오는 Stack push, pop 같은 존재이다.
ArrayList<E>
- 정말정말정말 많이 사용하는 것이다.
- 순서가 보장된다는게 중요한 class이다.
- ArrayList<String> list = new ArrayList<>();
- 메소드
- HashSet<E>과 사용방법은 동일하다.
- boolean add(E e ) : ArrayList객체에 객체를 저장한다. 맨 마지막 객체 다음에 객체가 저장된다.
- void clear() : ArrayList객체에 저장된 모든 객체를 삭제한다.
- boolean isEmpty() : ArrayList객체에 저장된 객체가 하나도 없으면 true를 반환한다.
- int size() : ArrayList객체에 저장된 객체의 갯수를 반환한다.
- boolean contains(Object e ): ArrayList객체에 지정된 객체가 존재하면 true를 반환한다.
- boolean remove(Obejct e ) : ArrayList객체에서 지정된 객체를 삭제한다.
- 맨 처음 발견된 객체만 삭제한다.
- 인덱스 메소드
- HashSet과 다르게 인덱스를 이용하여 더하거나 삭제가 가능하다.
- List계열들이 이런 기능을 가지고 있다.
- void add(int index, E e) : 지정된 인덱스에 객체를 추가한다. 기존 객체는 뒤로 이동된다.
- E set(int index, E e ) :지정된 인덱스에 저장된 객체를 새로운 객체와 교체한다.
- E remove(int index) :지정된 인덱스에 저장된 객체를 삭제한다.
- E get(int index) :지정된 인덱스 위치에 저장된 객체를 반환한다.
- for문의 조건식에서 list.size()로 바로 대입하여 데이터의 갯수를 조회하는 것은 실행성능을 나쁘게 만든다.
- int length = list.get(index);처럼 인덱스의 크기를 기본변수타입에 대입하여 조건식에 넣는 것도 좋다.
return타입의 확인
- public Set<E>XXX() {}
- XXX() 메소드를 호출하면 중복된 객체가 없는 자료구조 객체를 제공받게 됩니다.
- public List<E>XXX(){}
- XXX()메소드를 호출하면 저장했던 순서 그대로 다시 꺼낼 수 있는 자료구조 객체를 제공받게 됩니다.
자바 7이하의 버젼에서 타입추론이 등장하게 되었기 때문에 이전버젼의 경우는 <String>우측에 있는 제네릭에도 객체의 타입을 작성해주어야한다.
List
ArrayList<E>와 LinkedList<E>차이점
- ArrayList<E>는 순서대로 저장하고 순서대로 꺼내기 편하다.
- ArrayList<E> 중간에 저장된 객체를 삭제하거나 중간에 새로운객체를 추가할 때는 LinkedList<E>에 비해서 처리속도가 느리다.
- 데이터가 빈번하게 추가/ 삭제가 발생할 때는 LinkedList가 적합하다
- LinkedList<E>
- 데이터가 빈번하게 추가/삭제가 발생하는 경우에 사용한다.
- 데이터 추가/ 삭제로 인한 부하가 ArrayList<E>에 비해서 적다.
- 저장하는 방식의 차이
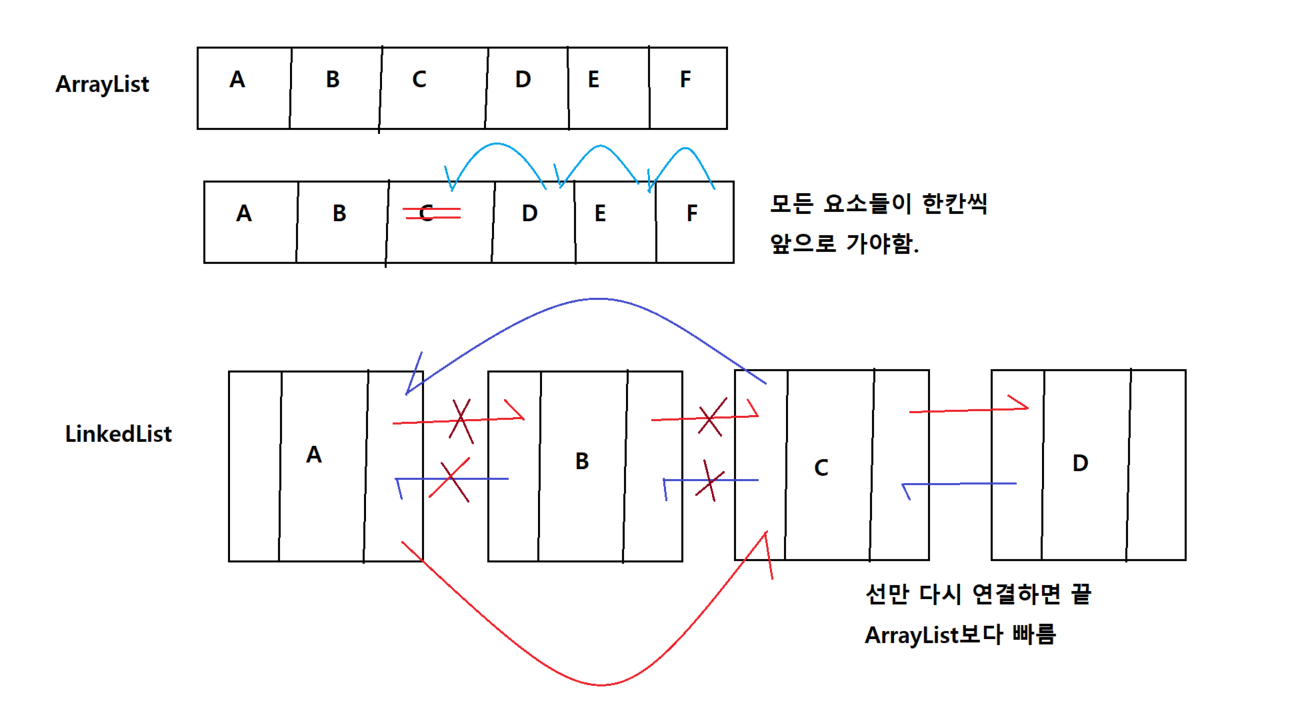

방식들이 전부 다 다르게 저장된다.
구현객체가 전부 다 달라도 동일한 방식으로 꺼내고 싶어서 1.2부터 추가가 되었다. 향상된 for문은 1.5부터 등장하였다.
Set, List
- 꺼내는 방법이 있어야한다.
- Collection 꺼내는 경우에는 향상된 for문을 사용하지만,
- 객체를 꺼내고 삭제할 때는 Iterator을 사용해야한다. -->기존의 소스를 변경해야하는 프로젝트가 많다.
Iterator<E> name = 꺼낼데이터name.Iterator();// 메소드를 호출한다. 일회용으로 한번 사용 후 끝이다.
Iterator<E> 꺼내는 방법에 대한 표준
- Interface Iterator<E> //collection<E>구현객체에 데이터를 반복처리하는 표준
- boolean hasNext( ); //자료구조구구현 객체에 반복처리할 데이터가 남아 있으면 true를 반환한다.
- E next(); //자료구조구현객체에서 객체를 꺼낸다.
- void remove(); //현재 반복처리 중인 객체를 자료구조구현객체에서 삭제한다.
public class ArrayList<E> extends AbstractList<E> implements List<E>{
- public boolean add(E e) {...}
- public E get(int index) {...}
- public class ArrayListIterator<E> umplements Iterator<E>{ //ArrayList객체에 저장된 객체를 반복처리할 수 있는 Iterator<E>구현 클래스 (멤버내부클래스)
- public boolean hasNaxt(){...} //ArrayList객체에 반복처리 할 데이터가 남아있으면 true를 반환
- public E next(){...} //ArrayList객체 반복처리할 다음 데이터를 반환
- public void remove(){...} //ArrayList객체에서 현재 반복처리한 데이터를 삭제한다.
- }
- }
모든 Collection<E>자료구조 자식들은 Iterator<E> iterator();을 무조건 구현하고 있다.
while()문 사용시점
- 특별한 객체와 연관되어 있을 경우
- 반복을 언제 끝내줘야 할지 알려주는 메소드와 함께해야함
- Iterator<E>내부의 hasNext();
- next()
- Enumaration<E>내부의 hasMoreElements()
- nextElement()
- boolean의 꺼내는 메소드들을 while문은 이렇게만 사용한다.
- 반복을 지속하는 메소드와 함께쓰는 것이 while문이다.
- while문으로 초기식, 조건식, 증감식을 흉내내지는 않는다.
- while문은 아래에서 예를 든 객체처럼 반복을 계속 실행해야하는지 알려주는 메소드가 있는 객체 경우에만 사용한다.
- Iterator<String> iter = names.iterator(); // ArraysList가 구현한 Iterator구현 객체를 획득한다.
- while(iter.hasNext()) { //반복
- String name = iter.next();
- name.remove();
- 배열의 remove를 사용하게 되면 맨 처음에 지정된 객체밖에 삭제가 되지 않는다.
- 데이터에 얼마나 있는지 모르기 때문에 여러번의 효율은 좋지 않다.
- 향상된 for문으로 사용하게 될 경우
- java.util.ConcurrentModificationException의 오류가 발생하게 된다.
- 추가는 가능하지만 삭제가 되지 않는다.

- Iterator의 경우 데이터를 아예 영구적으로 삭제할 때 사용할 수 있다.
- 1회용으로 사용하기 때문에 , 반복작업에 사용한 Iterator를 재사용할 수 없다.
- 다시 만들어서 사용해야한다.
반응형
'중앙 HTA (2106기) story > java API story' 카테고리의 다른 글
| java.util.유틸리티 클래스 (0) | 2021.10.08 |
|---|---|
| Map interface (0) | 2021.10.08 |
| Generic(제네릭) (0) | 2021.10.05 |
| System, Wrapper, math class (0) | 2021.10.03 |
| StringBuilder, StringBuffer (0) | 2021.10.03 |
'중앙 HTA (2106기) story/java API story' Related Articles
more




Comments